
The Hidden Cost of AI: The GPU Bill
AI model training typically consumes millions of dollars in GPU compute—a burden that shapes budgets, limits experimentation, and slows progress. The status quo: training a modern language model or vision transformer on ImageNet-1K can burn through thousands of GPU-hours. It’s not sustainable for startups, labs, or even large tech companies.
But what if you could cut your GPU bill by 87%—simply by changing the optimizer?
That’s the promise of Fisher-Orthogonal Projection (FOP), a latest research from the University of Oxford team. This article will walk you through why gradients aren’t noise, how FOP thinks like a terrain map, and what this means for your business, your model, and the future of AI.
The Flaw in How We Train Models
Modern deep learning relies on gradient descent: the optimizer nudges model parameters in a direction that should reduce the loss. But with large-scale training, the optimizer works with mini-batches—subsets of the training data—and averages their gradients to get a single update direction.
Here’s the catch: The gradient from each element in the batch is always different. The standard approach dismisses these differences as random noise and smooths them out for stability. But in reality, this “noise” is a crucial directional signal about the true shape of the loss landscape.
FOP: The Terrain-Aware Navigator
FOP treats the variance between gradients within a batch not as noise, but as a terrain map. It takes the average gradient (the main direction) and projects out the differences, constructing a geometry-aware, curvature-sensitive component that steers the optimizer away from walls and along the canyon floor—even when the main direction is straight ahead.
How it works:
Average gradient points the way.
Difference gradient acts as a terrain sensor, revealing whether the landscape is flat (safe to move fast) or has steep walls (slow down, stay in the canyon).
FOP combines both signals: It adds a “curvature-aware” step orthogonal to the main direction, ensuring it never fights itself or oversteps.
Result: Faster, more stable convergence, even at extreme batch sizes—the regime where SGD, AdamW, and even state-of-the-art KFAC fail.
In deep learning terms: FOP applies a Fisher-orthogonal correction on top of standard natural gradient descent (NGD). By preserving this intra-batch variance, FOP maintains information about the local curvature of the loss landscape, a signal that was previously lost in averaging.
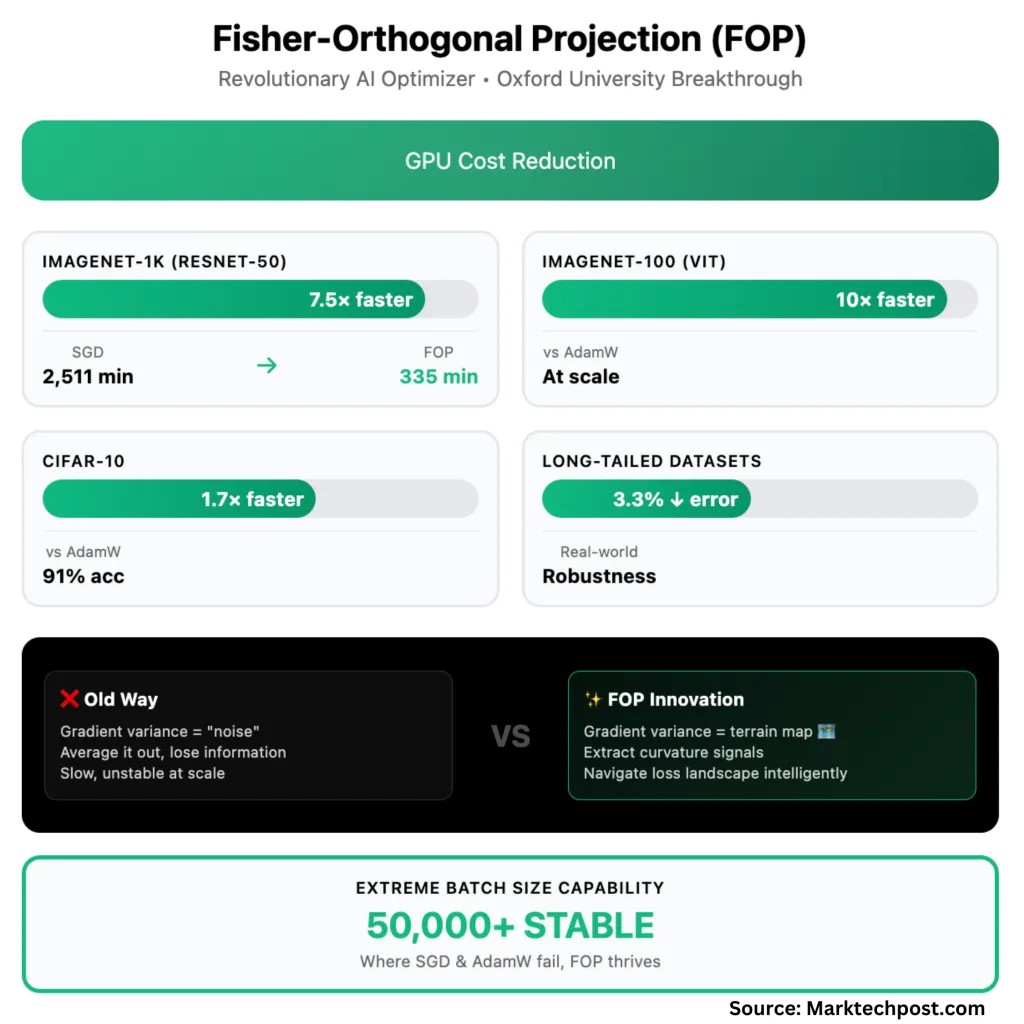
FOP in Practice: 7.5x Faster on ImageNet-1K
The results are dramatic:
ImageNet-1K (ResNet-50): To reach standard validation accuracy (75.9%), SGD takes 71 epochs and 2,511 minutes. FOP reaches the same accuracy in just 40 epochs and 335 minutes—a 7.5x wall-clock speedup.
CIFAR-10: FOP is 1.7x faster than AdamW, 1.3x faster than KFAC. At the largest batch size (50,000), only FOP reaches 91% accuracy; others fail entirely.
ImageNet-100 (Vision Transformer): FOP is up to 10x faster than AdamW, 2x faster than KFAC, at the largest batch sizes.
Long-tailed (imbalanced) datasets: FOP reduces Top-1 error by 2.3–3.3% over strong baselines—a meaningful gain for real-world, messy data.
Memory use: FOP’s peak GPU memory footprint is higher for small-scale jobs, but when distributed across many devices, it matches KFAC—and the time savings far outweigh the cost.
Scalability: FOP sustains convergence even when batch sizes climb into the tens of thousands—something no other optimizer tested could do. With more GPUs, training time drops almost linearly—unlike existing methods, which often degrade in parallel efficiency.
Why This Matters for Business, Practice, and Research
Business: An 87% reduction in training cost transforms the economics of AI development. This is not incremental. Teams can re-invest savings into larger, more ambitious models, or build a moat with faster, cheaper experimentation.
Practitioners: FOP is plug-and-play: The paper’s open-source code can be dropped into existing PyTorch workflows with a single line change and no extra tuning. If you use KFAC, you’re already halfway there.
Researchers: FOP redefines what “noise” is in gradient descent. Intra-batch variance is not only useful—it’s essential. Robustness on imbalanced data is a bonus for real-world deployment.
How FOP Changes the Landscape
Traditionally, big batches were a curse: They made SGD and AdamW unstable, and even KFAC (with its natural gradient curvature) fell apart. FOP turns this on its head. By preserving and leveraging intra-batch gradient variation, it unlocks stable, fast, scalable training at unprecedented batch sizes.
FOP is not a tweak—it’s a fundamental rethinking of what signals are valuable in optimization. The “noise” you average out today is your terrain map tomorrow.
Summary Table: FOP vs. Status Quo
Summary
Fisher-Orthogonal Projection (FOP) is a leap forward for large-scale AI training, delivering up to 7.5× faster convergence on datasets like ImageNet-1K at extremely large batch sizes, while also improving generalization—reducing error rates by 2.3–3.3% on challenging, imbalanced benchmarks. Unlike conventional optimizers, FOP extracts and leverages gradient variance to navigate the true curvature of the loss landscape, making use of information that was previously discarded as “noise.” This not only slashes GPU compute costs—potentially by 87%—but also enables researchers and companies to train bigger models, iterate faster, and maintain robust performance even on real-world, uneven data. With a plug-and-play PyTorch implementation and minimal tuning, FOP offers a practical, scalable path for the next generation of machine learning at scale.
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.